Executive Summary
Teams building on open source LLMs usually face the same decision early on: call a hosted token API, or self-host the model on rented GPUs?
A common belief is that self-hosting is always cheaper once you hit real scale. We found that this is not a safe default. In many realistic single-pass workloads, cost-leader APIs are surprisingly hard to beat on pure dollars per token - especially once you account for utilization and operational overhead. Self-hosting behaves differently because it is a capacity bet: your effective cost depends heavily on how busy you can keep the GPUs, and when utilization drops, costs rise quickly while API pricing stays flat.
We also found that break-even is not always attainable. For some model and workload combinations, self-hosting would require near-perfect utilization to match API costs. When the break-even utilization lands above 100%, self-hosting simply will not beat the API baseline under those assumptions.
But there is a clear turning point. As products become multi-step and reuse-heavy token economics can flip. This is the norm in agentic systems like coding agents, customer service agents, and research agents. Internal model calls per user query multiply, and repeated context becomes a real cost driver in API mode. Cached input pricing helps, but it does not always remove the scaling effect. In reuse-heavy agentic workflows, self-hosting can become structurally cheaper beyond a crossover point.
In the sections that follow, we lay out the framework we used, along with charts and assumptions you can adapt to your own workloads.
Two deployment modes for open source models
Mode 1: Token APIs
In API mode, you call a hosted endpoint and pay per token - split into input tokens (your prompt plus context) and output tokens (the generated completion). APIs are easy to integrate, scale well for spiky demand, and shift most of the operational burden to the provider. Cost is mostly linear in the number of tokens processed.
Mode 2: Self-hosting on rented GPUs
In self-host mode, you rent GPUs and run the model yourself (we use vLLM as the serving stack). Your effective cost is driven by the GPU price per hour, the throughput you achieve under your specific workload, the utilization you sustain over time, and the operational overhead of running the serving stack.
For this analysis, we focus on three representative open source models: Qwen3-32B, DeepSeek V3.2, and GLM 4.7. We also focus on NVIDIA B200 economics, because newer hardware generations shift the cost curve meaningfully and we want you to reason about where the world is heading - not just where it has been.
Workload regimes and operational reality
Tokens do not impose uniform compute cost during inference. Input tokens drive prefill, where the model processes the entire prompt to build the KV cache. Output tokens drive decode, where the model generates tokens autoregressively. These phases stress the system differently: large prompts and long context windows can reduce throughput due to memory movement during prefill, while long generations can saturate decode and limit how many concurrent requests the server can sustain.
This is why "dollars per million tokens" is not a single number in practice - it depends on the shape of your traffic and how your tokens split between prefill and decode.
To keep this analysis grounded, we use five standard workload profiles (drawn from the GPUStack vLLM study) that vary prompt and completion length in ways that map to real products:
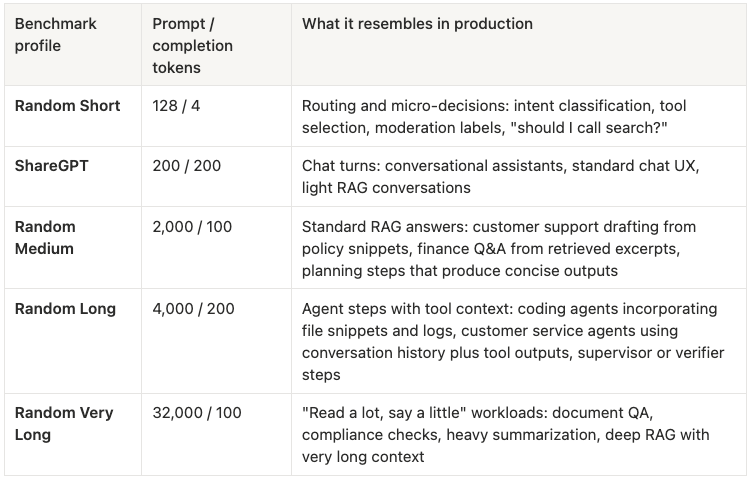
Table 1: Analysis is based on five standard workload profiles that vary by prompt and completion lengths in ways that map to real products.
This mapping also clarifies how to think about agentic systems. Most agents are not a single workload regime - they are k internal model calls per user task, where each step often resembles Random Medium or Random Long, sometimes punctuated by Random Very Long context ingestion, and occasionally preceded by Random Short routing calls.
A coding agent, for example, typically executes multiple long-context steps (plan, edit, test, debug, patch), and each step reuses much of the same prefix context: system instructions, repo context, tool outputs. That is exactly the setting where context reuse and caching become first-order cost drivers. Customer service agents look similar, with repeated policy context, conversation history, and tool results flowing across multiple internal calls. Research and retrieval agents follow the same pattern: query planning, searching, reading, synthesizing - each step building on shared context from the steps before it.
We reference these agent archetypes throughout the analysis because they represent the workloads that a growing number of teams are actually building, and they are the workloads where the API-vs-self-host decision gets most interesting.
1) Single-pass: cost-leader APIs are hard to beat
The first result is the baseline many teams should start with: single-pass token economics are not automatically favorable for self-hosting, even on modern GPUs.
We compare API pricing using DeepInfra list prices (at the time of analysis) against self-host pricing derived from vLLM throughput baselines published by GPUStack, which we scale to B200 as an estimate. For the self-host case, we assume 70% utilization and a 15% overhead adder.
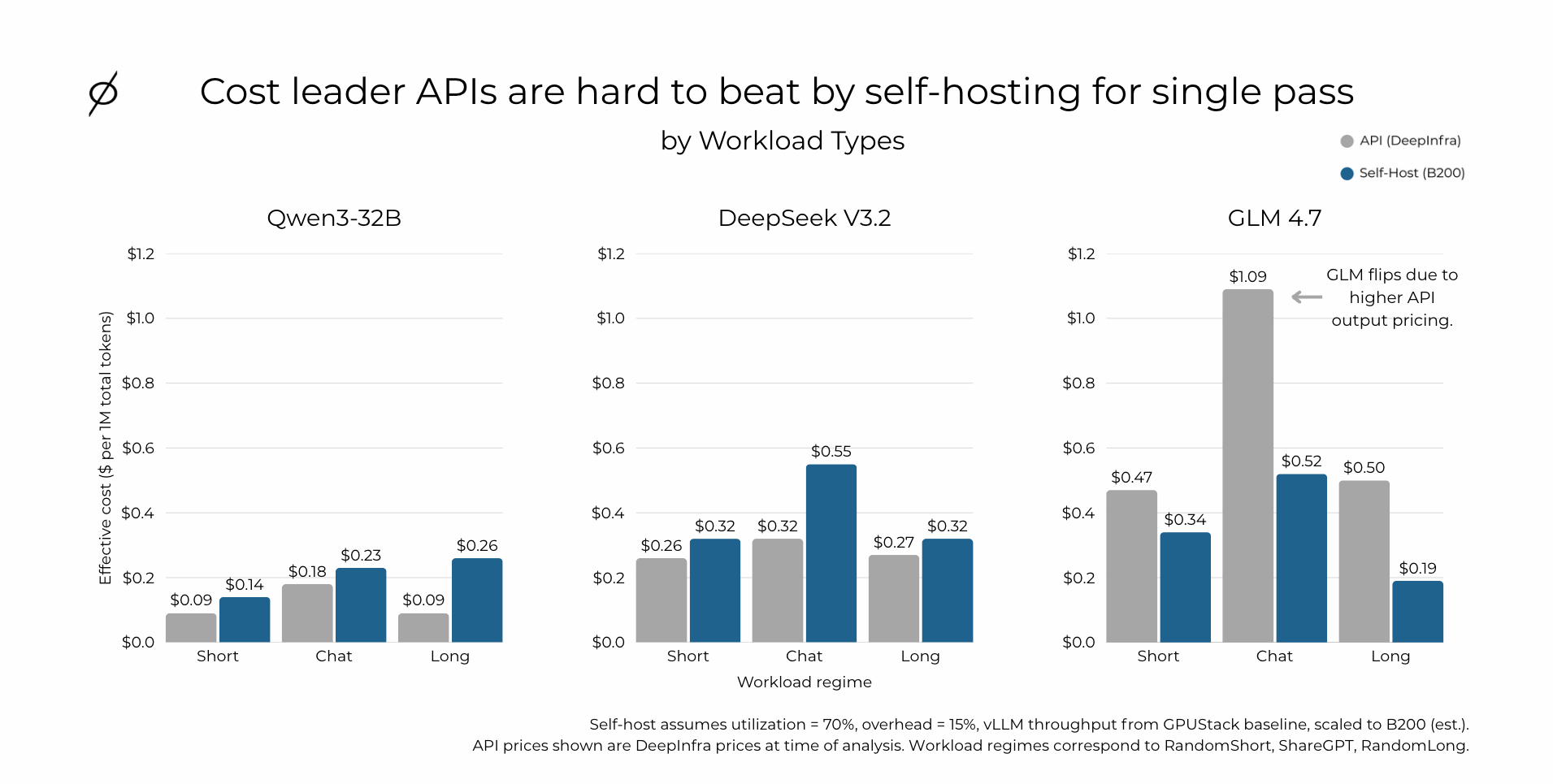
Figure 1: Cost-leader APIs are hard to beat by self-hosting for single pass. Bar chart comparing API (DeepInfra) vs Self-Host (B200) effective cost per 1M total tokens across Short, Chat, and Long workload regimes for Qwen3-32B, DeepSeek V3.2, and GLM 4.7. Self-host assumes utilization = 70%, overhead = 15%, vLLM throughput from GPUStack baseline scaled to B200.
The results are straightforward:
For Qwen3-32B and DeepSeek V3.2, the cost-leader API is cheaper across all three regimes in this setup. The margins are not razor-thin - the API holds a consistent edge at our assumed utilization and overhead.
GLM 4.7 flips. Self-hosting is cheaper in these regimes because GLM's API output pricing is materially higher. This is an important signal: provider pricing strategy and model-specific token pricing can dominate the outcome independent of the underlying hardware economics.
The practical implication is that "self-host always wins" is not a reliable starting point. You need to evaluate model-by-model, provider-by-provider, and you should expect the best API providers to be extremely competitive on single-pass economics. If your product is primarily single-pass - a chatbot, a one-shot classifier, a straightforward RAG pipeline - starting with an API is often the lower-risk, lower-cost path.
2) High utilization is key to profitable self-hosting
API token cost is mostly linear in tokens. Self-host cost is not.
Self-hosting is a capacity purchase: you pay for GPU-hours whether or not those GPUs are doing useful token work. Your effective cost per token is a direct function of how much of the day your GPUs are actually busy. If utilization falls, your cost per token rises quickly. In practice, utilization gets pulled down by spiky demand, low concurrency, queueing and bursty traffic patterns, and the operational slack teams intentionally maintain for reliability.
The chart below shows how this plays out for the Chat (ShareGPT) workload regime, but the same dynamic applies across all regimes:
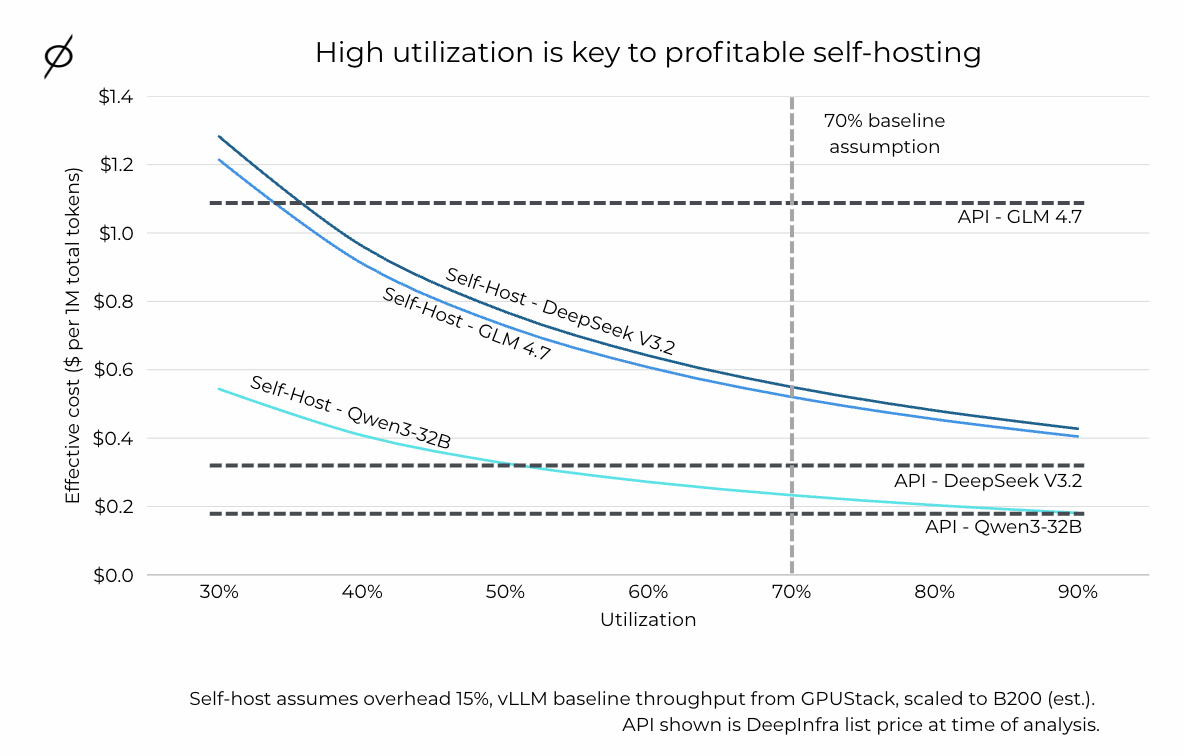
Figure 2: High utilization is key to profitable self-hosting. Line chart showing effective cost ($ per 1M total tokens) vs utilization (30%–90%) for self-hosted Qwen3-32B, DeepSeek V3.2, and GLM 4.7, with horizontal dashed lines for each model's API price. The 70% baseline assumption is marked. Self-host assumes overhead = 15%, vLLM baseline throughput from GPUStack scaled to B200.
At low utilization, all three self-hosted models are more expensive than their API counterparts. As utilization rises, the self-host curves drop - but for Qwen3-32B and DeepSeek V3.2, you need to be running quite hot before you cross the API baseline. GLM 4.7 crosses earlier because its API price is higher, giving self-hosting more room.
The takeaway: if you cannot keep GPUs consistently busy, token APIs often win on both cost and operational simplicity. Self-host economics improve dramatically as utilization rises, which means steady load, high concurrency, or effective batching is usually a prerequisite for self-hosting to pencil out. Many teams overestimate their real-world utilization - headroom for reliability, traffic bursts, and queueing effects can pull utilization down enough to erase the apparent savings you see in peak throughput benchmarks.
3) Break-even utilization: when self-hosting cannot win
The utilization curve is useful, but many teams want a simpler decision boundary: "What utilization do we need for self-hosting to match the API?"
That is what break-even utilization captures. For each model and workload regime, we compute the utilization at which the self-host blended cost per million tokens equals the API blended cost per million tokens.
To make this actionable for teams building agentic products, we map the benchmark workload regimes to the agent archetypes they most closely resemble: Chat Agents align with ShareGPT-like behavior, Customer Service Agents often sit in the Medium-to-Long regime depending on how much history and tool output they carry, Coding Agents tend to be Long per step and repeated across many steps, and Doc Q&A is typically Very Long, where a large context window dominates cost. These labels are not perfect classifications - they are intended to reflect the workloads teams actually deploy, and to make the utilization story tangible for anyone building multi-step AI products.
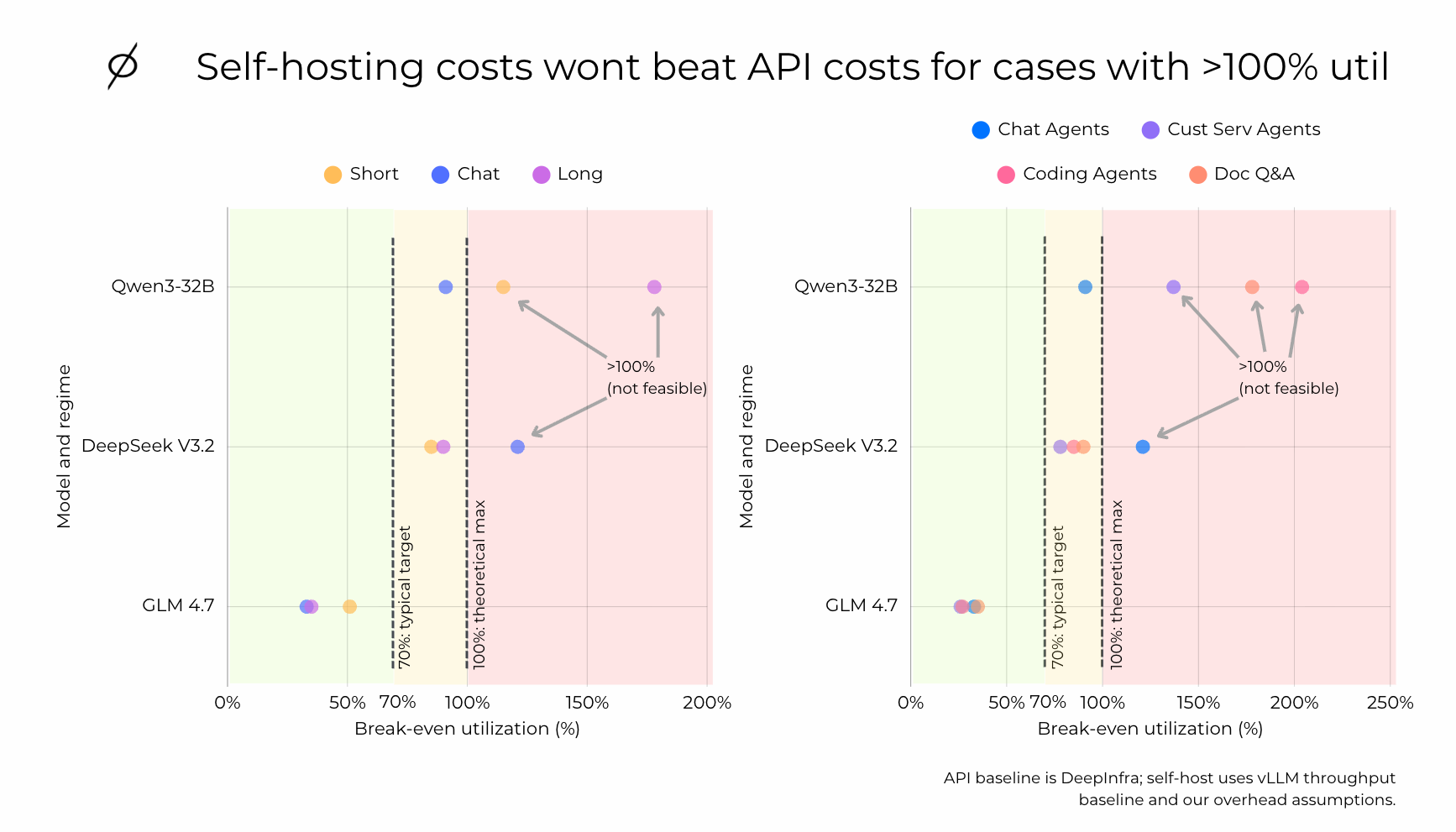
Figure 3: Self-hosting costs won't beat API costs for cases with over 100% utilization requirement. Scatter plot showing break-even utilization (%) by model (Qwen3-32B, DeepSeek V3.2, GLM 4.7) and agent archetype (Chat Agents, Customer Service Agents, Coding Agents, Doc Q&A). Green zone (left of 70%) = self-hosting wins easily. Yellow zone (70%–100%) = self-hosting wins only at high utilization. Red zone (>100%) = self-hosting cannot beat API. API baseline is DeepInfra; self-host uses vLLM throughput baseline and overhead assumptions.
Points in the green zone (left of the 70% line) indicate cases where self-hosting can beat the API even at moderate utilization. These are the scenarios where self-host economics are forgiving - you do not need to run GPUs exceptionally hot to come out ahead.
Points in the yellow zone (clustered near 100%) can still favor self-hosting, but only if you operate close to peak packing with consistently high utilization. In practice, that requires steady demand, strong batching or concurrency, and minimal idle time.
Points in the red zone (beyond 100%) indicate cases where self-hosting will not beat the API under the stated assumptions - break-even would require more than full utilization, which is not feasible. These are strong signals that a cost-leader API is likely to remain the lower-cost option unless something changes: meaningfully higher throughput from serving optimizations, lower GPU rental cost, or lower operational overhead.
4) Multi-step agentic workflows are where self-hosting becomes cheaper
Everything above assumes a single model call per user query. But that assumption misses a major reality: many production systems - especially agentic ones - do far more than one call per user task.
This is where the economics get interesting, and where we think the most important insight of this analysis lives.
A conversational agent might be single-pass in its simplest form, but it quickly becomes multi-step once you add retrieval, tool use, planning, and verification. A coding agent commonly iterates through plan, code, test, debug, and patch loops. A customer service agent follows similar patterns: intent classification, policy lookup, drafting, compliance checks, escalation routing, and structured logging.
In all of these workflows, a large fraction of the input context is repeated across steps: the system prompt, user history, retrieved context, tool outputs, and intermediate reasoning traces. That repetition inflates paid input tokens in API mode, even if each individual call is priced competitively. Some providers offer cached input pricing, which helps - but it does not eliminate the underlying scaling behavior in multi-step workflows.
To make this concrete, we modeled cost per user query as a function of k internal model calls per query, using real values from our Tau2 Bench agentic runs on DeepSeek V3.2:
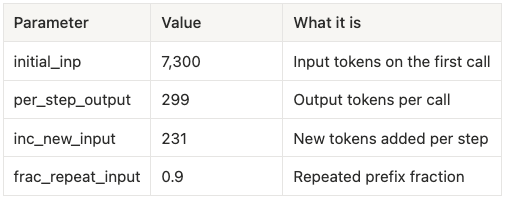
Table 2: Assumptions made for our modeling of agentic workflows.
API pricing uses DeepInfra input, cached input, and output prices at time of analysis.
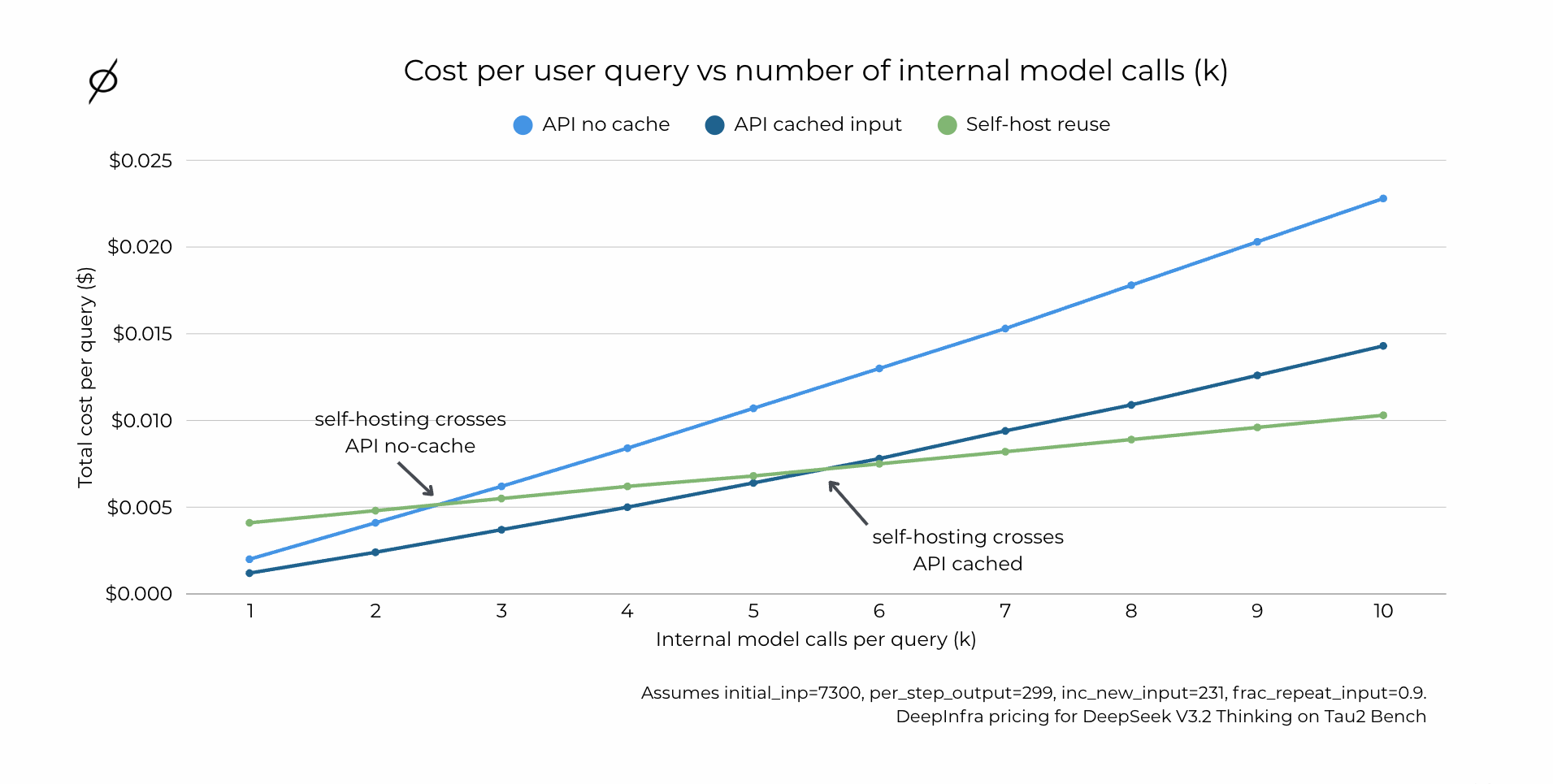
Figure 4: Cost per user query vs number of internal model calls (k). Line chart showing total cost per query ($) as k increases from 1 to 10, with three lines: API no cache, API cached input, and Self-host reuse. Crossover points are labeled where self-hosting becomes cheaper than each API pricing mode. Assumes initial_inp=7300, per_step_output=299, inc_new_input=231, frac_repeat_input=0.9. DeepInfra pricing for DeepSeek V3.2 Thinking on Tau2 Bench.
Even if the API wins at k = 1, as the number of internal model calls per task increases, repeated context begins to dominate the bill and self-hosting with reuse becomes the lower-cost option. Cached input pricing narrows the gap, but it does not remove the underlying scaling behavior in reuse-heavy workflows.
In our DeepSeek V3.2 example, at k = 20 agentic calls per task (extrapolated from the chart above), self-hosting is approximately 2× cheaper than API with cached input and approximately 3× cheaper than API without cache - driven primarily by avoiding repeatedly paying for the same input context.
A hybrid approach
A practical way to operationalize this is a hybrid architecture: route simple, single-pass requests to a cost-leader API, and route requests that are likely to be multi-step or reuse-heavy to a smaller self-hosted capacity pool. This keeps operational complexity contained while capturing most of the economic upside when agentic workflows expand the number of internal calls per user task.
How many internal model calls do agents actually make?
In production, there is no universal "typical k" - it depends on workflow design, tool availability, guardrails, and how aggressively you cap retries. But we can anchor on what popular agent frameworks assume by default and what public agent benchmarks observe when agents run multi-step tool workflows.
As one reference point, LangChain's AgentExecutor defaults to a maximum of 15 iterations, which is a reasonable proxy for the order of magnitude many teams start with before tightening or loosening caps. At the same time, multi-step behavior can extend well beyond a handful of calls - some agentic workflows are explicitly composed of tens to hundreds of LLM calls, and benchmarks measuring end-to-end tool execution show per-task turns quickly moving into the teens and beyond.
Here is a practical mapping to help you contextualize the chart above (ranges are rough, but directionally useful):
Chat assistants (non-agentic, single response): usually k = 1, sometimes 2 if you add a lightweight verifier or safety pass.
Customer support agents: often k ≈ 3–12 - retrieve policy, draft response, verify, optional tool lookups, with retries for edge cases.
Web search and research agents: often k ≈ 5–15 - query planning, search, open and read multiple pages, synthesis, and citation checking. Tool-heavy runs commonly land in the low teens or higher.
Finance and analytics agents: often k ≈ 5–20 - multi-document retrieval, extraction, calculations, reconciliation, and a final write-up, especially when calling tools for tables, spreadsheets, or structured data.
Coding agents: often k ≈ 8–30 - plan, inspect files, run tests, patch, rerun, iterate. The long tail can climb much higher in complex tasks.
How to connect this back to the cost chart: if your product's agent task regularly lives above the crossover point - sustained multi-step behavior rather than k close to 1 - then the case for self-hosted reuse strengthens quickly, even if the single-pass economics look unfavorable.
Decision framework: which bucket are you in?
Bucket A: APIs usually win
APIs are the better default when your application is primarily single-pass and your traffic is spiky or unpredictable. Paying per token maps cleanly to usage, you benefit from managed scaling without staffing a serving stack, and operational complexity stays low. This is often the right choice when your team wants to move fast and does not need deep control over serving internals.
Bucket B: Self-hosting starts to win
Self-hosting becomes compelling when your workflow is multi-step and reuse-heavy - the norm in agentic systems where one user request triggers multiple internal model calls. If you reuse significant context across steps and can keep GPUs busy through steady demand, batching, or high concurrency, the economics shift in your favor. Self-hosting is also a better fit when you need tight control over caching, routing, instrumentation, and execution behavior, since those levers can meaningfully affect both cost and performance.
A quick checklist
If you are trying to decide, ask yourself:
- Can we keep GPUs above a meaningful utilization target (say, 70%+)?
- Do we make more than one model call per user query?
- Is a large part of our input context repeated across steps?
- Do we need control over batching, caching, routing, or tail latency?
- Are we running custom or fine-tuned weights that are not available via APIs?
If you answer yes to several of these, self-hosting is more likely to be structurally correct - even if a cost-leader API looks good on single-pass economics.
What this post does not cover
Two real factors often dominate the final decision that we intentionally left out of scope: the engineering and operational burden of running your own serving stack, and the reliability and scaling guarantees you get from managed APIs versus DIY deployments. For early-stage teams, these can easily outweigh pure token economics.
We also did not account for the hidden costs of API rate limits and throttling, which can cap throughput during peaks and slow down product scaling even when the per-token price looks attractive.
Finally, we did not evaluate buying or owning GPUs. This analysis focuses only on self-hosting using rented GPU capacity. Owning hardware can materially change the economics depending on utilization, financing, depreciation, and operational constraints.
Closing
Self-hosting is not automatically cheaper. For single-pass inference - especially with spiky demand - cost-leader APIs can be hard to beat on both cost and operational simplicity.
Self-hosting becomes compelling when you can run hot. Utilization is the lever, and break-even often requires high utilization for many model and workload combinations.
But multi-step and reuse-heavy workflows - the kind that power coding agents, customer support agents, research agents, and tool-using systems - are where self-hosting is most likely to be economically better. As internal calls per query grow, repeated context becomes a real cost driver in API mode. Cached input pricing helps, but self-hosting often achieves a much lower effective token cost once you account for reuse across steps.
The practical takeaway: choose based on your workload.
If you are single-pass and spiky, start with APIs.
If you are agentic, multi-step, and can sustain utilization, self-hosting is often the lower-cost path.
Appendix
Methodology and disclaimers
We include this section because most comparisons accidentally mix assumptions, and we want you to be able to rerun these numbers for your own setup.
- Throughput source. Workload throughput baselines come from a published GPUStack vLLM study and reflect high-concurrency throughput rather than single-request latency.
- B200 scaling. We scale H100 and H200 measurements to B200 using separate multipliers for prefill and decode. Treat these as directional estimates, not universal constants.
- Optimizations can move the curve. There are serving optimizations (speculative decoding, quantization, chunked prefill, prefix caching) that can materially increase throughput and make self-hosting more attractive. Many hosted inference platforms likely use aggressive optimizations internally, which helps explain very low token prices.
- API prices are a snapshot. Token prices change frequently. Treat the API baseline as "at time of analysis" and rerun the numbers for your own snapshot.
Inputs block
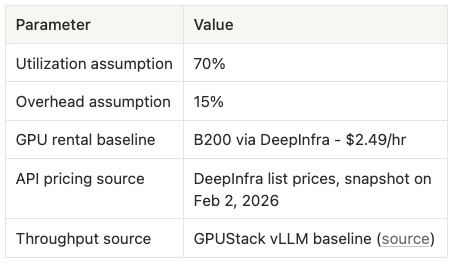
Table 3: Input assumptions made for self hosting.
A short hardware note: why B200 changes the slope
It is worth adding a hardware lens, because conclusions drawn from earlier GPU generations do not always carry forward cleanly.
B200-class hardware can materially improve effective throughput and therefore reduce cost per token - especially when the serving stack takes advantage of newer quantization paths and kernels. Even if APIs are competitive today, the self-host curve can move as hardware improves.
In our analysis, we used scaling multipliers to estimate B200 throughput from H100 and H200 measurements, separated for prefill and decode. These are directional estimates, not universal constants. The important point for decision-making is that break-even points are not static. As hardware and serving stacks evolve, the boundary between "API is cheaper" and "self-host is cheaper" shifts - and teams should revisit their assumptions periodically rather than treating a single analysis as permanent.